
Tree Searching Algorithms
Created | Updated May 23, 2008
You can't get there from here...
Studying a map carefully, a lorry driver decides that the best way to get to Moscow is to go via Berlin and Warsaw. After several minutes of thought, a chess grandmaster advances a pawn a couple of squares and looks confident. An expert in '15-puzzles' chooses a few moves to turn a jumbled mass of numbers into a harmonious pattern.
What do all these things have in common? The answer is that they're all examples of search problems, and they're all tasks that programmers have tried to get computers to solve, with varying degrees of success. Indeed, Volume 3 of Donald Knuth's definitive work, The Art of Computer Programming, is entirely about searching and sorting.
Descriptions and Abstractions
The best way to describe these problems is as a collection of states and actions. A state might be something like 'I am in Paris' or 'I am in Berlin' - though it could be much more complicated, like the state of a chessboard: giving the positions of each piece. An action is something like 'move the queen one square to the left', or 'take the A416 to Doncaster'. Each action moves us into another state, and an action there moves us into yet another state, and so on.
Some of the difficulty is deciding what is relevant to the problem, and what is not. For example, when playing chess, all that matters is what square the pieces are on; it doesn't matter how old the chess set is, nor does it matter which way the pieces are facing. Similarly, once a piece is off the board we no longer care what happens to it - if it is eaten by the cat it will have no effect on the game (although it probably will on the cat). This process is called abstraction, and is easy to do, but very hard to teach a computer to do.
Tree-based Solutions
Many of the algorithms for solving these problems have as their basis the concept of searching and expanding a tree-like structure of states linked by actions until a solution is found. The basic concept of a tree is that the initial state is placed at the top, and then an arrow is drawn downwards for each possible action, and at the end of each arrow the appropriate new state is placed. States which represent the goals of the problem are called solution nodes, and the aim is to try and find a path to a solution node. Supposedly, the whole thing looks like an upside down tree. Here's an example:
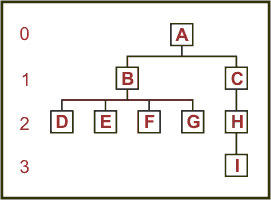
In this example:
The root node is A because it is highest in the tree.
The depth of a node is the distance from the root, so A is at depth zero; B and C are at depth one; D, E, F, G, and H are at depth two; and I is at depth three.
The parent of a node is the node immediately above it, so that C is the parent of H.
The child of a node is one of the nodes immediately below it, so that B has four children. Nodes with no children are called leaf nodes (or external nodes), while nodes with one or more children are called branch nodes (or internal nodes).
These trees, however, can sometimes be far too big to hold in a computer's memory, and some of them are even infinite in size, ie they have an infinite number of nodes in them. Infinite trees don't require one node to have an infinite number of children - just a finite amount of children, a finite amount of grandchildren, a finite amount of great-grandchildren, and so on for ever.
Because of this and other considerations, it is better to use partially expanded trees. The idea is that some of the nodes are expanded, and some are collapsed. Nodes which are collapsed have all of their actions invisible, and all of the states directly below them invisible too. To expand a collapsed node, you generate all the actions, and add them, and you also generate all the states directly below them, but keep them collapsed. The advantage of this method is that you only need to expand some of the nodes at any one time.
Help for the Helpless
In most problems there's usually an indication as to which action is appropriate at which stage. When travelling from New York to Washington, it would make sense to pick directions which take us in roughly the right direction - going via Beijing is probably not the best idea unless you really want to take the scenic route. However, sometimes there are no such hints, and the earliest indication that you're close to your destination is when you're actually there.
The problem with all these undirected searches is that they suffer from a combinatorial explosion. In other words, as the complexity of the problem increases, the amount of time (and space, in some algorithms) required to solve it grows exponentially. This will quickly swamp even the largest computer.
Depth-first Search
In a depth-first search, the idea is to keep going until you reach your destination, or you find yourself in a dead end. If you get to the destination, then the problem's solved. Otherwise you are at a dead end, and must backtrack until you find a place where you had a choice of actions, then take the other action. It's called depth-first because you quickly go to states which are very 'deep' in the tree.
Depth-first searching is very fast because it doesn't need to store much state information - only a short queue of nodes to be expanded. This queue grows at roughly the same rate as the depth of the node being examined, so quite large trees can be examined with little memory requirements. Sadly the algorithm often gets caught in infinite loops when used on infinite trees. For example, when planning a route, you might get stuck down the Paris -> Berlin -> Paris -> Berlin -> Paris... part of the tree, which will never yield a solution.
Another problem is that certain trees will always take a long time for depth-first searching to find a solution. For example, there may be a solution at depth one, but if a depth-first search doesn't choose the correct node first, then it will take a long time to find it. Random depth-first is an attempt to improve the average behaviour by choosing a random node to expand, rather than the leftmost one, as in normal depth-first. This somewhat reduces the problem in certain worst-case scenarios where every node is a solution except the nodes that a depth-first search looks at.
Breadth-first Search
The breadth-first search is diametrically opposed to the depth-first search. Rather than going straight to the highest depth, as in depth-first searching, the breadth-first algorithm searches all the nodes at depth one first, then all the nodes at depth two, and so on. The advantage of this, compared to depth-first, is that infinite loops can more easily be avoided provided there is a solution at some point. The disadvantage is that it requires much more memory, as all of the tree expanded so far has to be stored, rather than just a short queue. The other advantage is that depth-first occasionally finds a solution which is a long way from the initial state (the root node).
Breadth-first searching is guaranteed to find the solution that is closest to the initial node. In general, this means that it will be a 'better' solution, with lower cost (ie, computer processing and storage requirements) associated with it.
A variation of the breadth-first search is the uniform cost search. Rather than expanding the nodes in order of their depth, they are expanded in the order of the cost it would take to get to that depth. For example, a flight from London to New York may be only one single action in our tree, but it may be very costly. By contrast, a flight from London to Paris, and from there to Berlin, will be two actions - and hence at a depth of two - but be very much less costly. Uniform cost searching always finds the cheapest solution.
Iterative Deepening
Iterative deepening aims to combine the advantages of breadth-first and depth-first searching. Initially it performs a depth-first search, but limits the depth to depth one. Then it performs a depth-first search with the depth limited to depth two. It continues performing these passes, until eventually it finds a solution. This means that it will find the same solution as would be found by a breadth-first search, but only uses as much memory as a depth-first search.
There is one slight problem: it needs to look at the same nodes many times. For example, if it expands to depth five before finding a solution, then the root node will be checked five times. In practice this is rarely a problem because of the exponential nature of tree branching. For example, if there are an average of 10 available actions at each state, and the solution is at depth five, then nearly 90% of the nodes of the tree that you look at will be at depth five. Therefore the amount of repetition work that has to be performed is actually fairly minimal.
Optimisation
One simple optimisation is bidirectional searching. The idea of bidirectional searching is that as well and searching forward from the initial state, you search backwards from the solution state, and hence there are two concurrent search trees instead of one. When the two search trees have a state in common, you have found a path from the initial state to a solution state. This can be much more efficient, but there is a problem: finding when the two search trees cross its actually really rather complicated. It can be done using a hash look-up table, but this requires keeping all the nodes in main memory, which is, yet again, quite slow.
Another option is to try and avoid repeated states. For example, when planning a road trip one would not consider a journey which went from Paris to Berlin and then back to Paris again: this would be a silly idea. There are actually two options here: one can simply refuse to return to any state that one just left, but this does not help for larger loops, such as Paris -> Berlin -> Rome -> Paris. The more complicated option is to try to detect and eliminate larger loops, which is difficult but can be done.
Knowing what You're Doing
When we know something about the problem, life becomes much easier. For example, we might know that Paris is closer to Berlin than New York. Therefore, if you're travelling from London to Berlin it makes more sense to go first to Paris, rather than going to, say, New York. This information is rarely exact (otherwise it isn't much of a problem), but it can help significantly.
Often, the information we have is an estimate of the distance from a given node to the nearest solution node. This information is called a heuristic. This estimate could be based on a number of things; for example we might use the distance 'as the crow flies' to estimate the distance as the car drives. In a chess game we might use the number of pieces we have taken as an estimate of how close we are to winning.
Greedy Search
In a greedy search, we take the path which minimises the estimated distance to the target. In other words, we expand the node which has the lowest value of the heuristic. These algorithms are fast, and hence very useful, but they will not always find the optimal solution. They also suffer from some of the problems of depth-first searches in that they can get caught up in infinite branches of the tree.
The A* Search
As greedy searching is to depth-first searching, so A* searching is to breadth-first searching. The A* search minimises the estimated total cost to get from the initial state to the solution state. In other words, we add the (known) cost to get from the initial node to the candidate for expansion, and then add the estimated cost to get from there to a solution. Provided that the heuristic used is optimistic - ie, it always underestimates the total cost - an A* search will always return the best solution.
The only problem is that, like breadth-first searching, it uses an awful lot of memory. This can be solved with a variation on iterative deepening, in which case it is known as an IDA* search. Alternatively one can use the more complicated memory-bounded search. Memory-bounded searches are pretty clever: they only collapse a node when it would otherwise cause the computer to run out of memory. Unfortunately, they are also really rather complicated.
Choosing Heuristics
After designing the algorithm, all that remains is to find a good heuristic. This is a big topic in itself, but there are some good general guidelines. Good heuristics should be fast to calculate, but still as accurate as possible at estimating the distance to the solution.
In the 8-puzzle game, the aim is to find a solution with all eight tiles in the correct position, and the following heuristics can be used, in order of accuracy:
Are all eight tiles in the correct position?
How many tiles are in the correct position?
What is the Manhattan Distance1 of each tile from its correct position?
In 1993, a program called ABSOLVER was written which could automatically generate heuristics for a problem. It generated a heuristic for the 8-puzzle better than any of these, and it also generated the first useful heuristic for the Rubik's Cube puzzle. However, humans are still generally better at heuristics: Deep Blue2 owes much of its success to a huge team of chess experts helping to refine its heuristics.